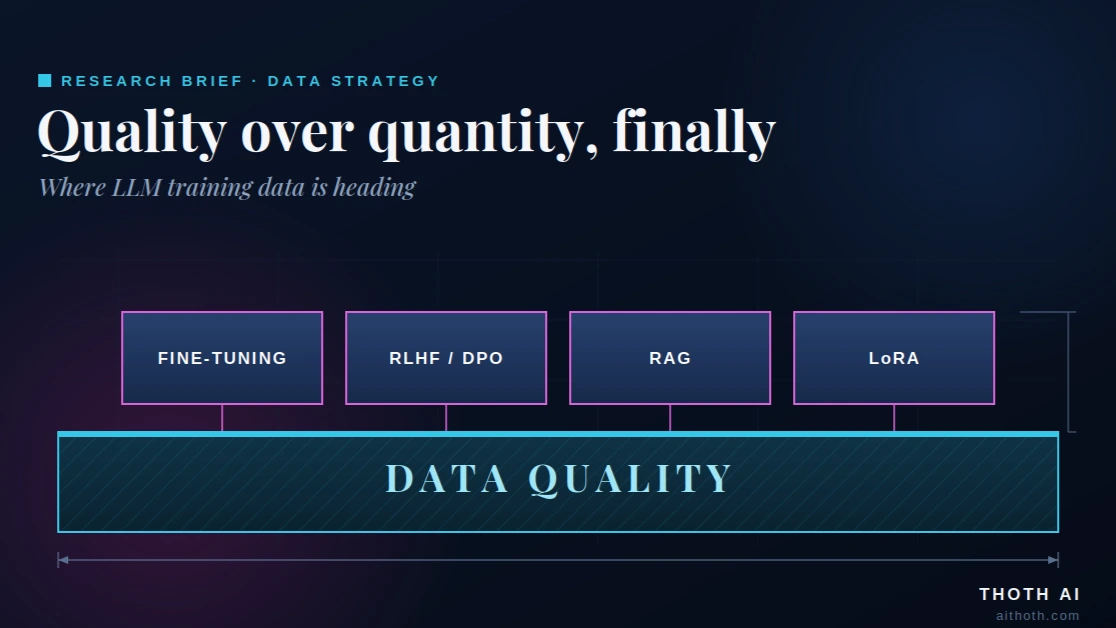
The 42× number that should change how you scope annotation projects
If you’ve worked on NLP for low-resource languages — Yoruba, Quechua, Tigrinya, Hmong — you know the math is brutal. Native speakers with domain expertise are scarce. Their time is
If you’ve worked on NLP for low-resource languages — Yoruba, Quechua, Tigrinya, Hmong — you know the math is brutal. Native speakers with domain expertise are scarce. Their time is
If you’ve worked on NLP for low-resource languages — Yoruba, Quechua, Tigrinya, Hmong — you know the math is brutal. Native speakers with domain expertise are scarce. Their time is expensive. The data needs are enormous. And you can’t bootstrap from a “close enough” language without inheriting serious bias. A