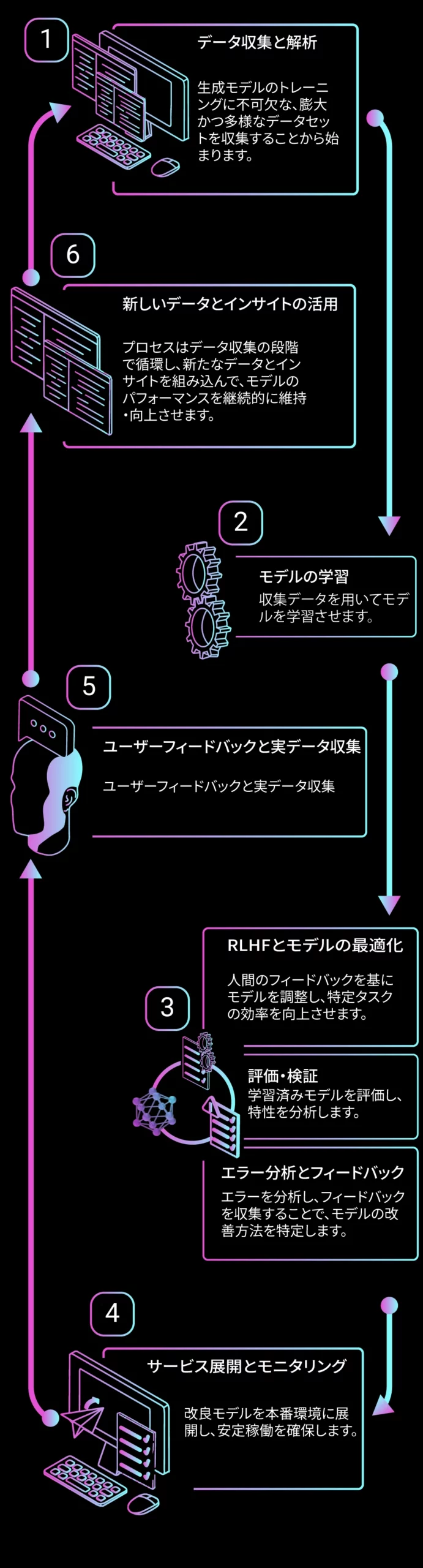
人間のフィードバックを活用した強化学習(RLHF)によって生成AIモデルを改良、それにより生成AIアプリケーションの開発効率が向上します。

生成型AIの役割は、単に人間の能力をAIに置き換えることではなく、幅広いタスクや業界において、サポートの高い付加価値、支援、自動化を提供することにより人間の能力を強化することです。AIと人間の両方の強みを活用することで、組織は効率性、イノベーション、生産性を向上させることができます。
顧客へのバリエーションに富んだ提案をすることにより、新しいコンテンツのアイデアを創出します。
顧客の質問に対して確実に結果を積み上げ、有益な情報を提供いたします。
画像、ビデオ、サウンドの品質を向上させることにより、欠陥部分への補正を実現、違和感のないクオリティを提供します。
Thoth AIは専門家監修型(EIL)を介入させることにより、生成AIの学習プロセスと判断アルゴリズムを最適化。AIの誤生成(幻覚)などの課題を検知・修正し、出力の高精度化と信頼性向上を実現します。
大規模な言語処理モデル
基盤モデル
大規模画像処理AI

当社の最大の資産は、業界の最先端で活躍するプロフェッショナルで構成されたチームです。多岐にわたる専門知識と深い知見で、パートナー企業の挑戦をより現実的なものにします。
当社はパートナー企業固有の課題を深く理解し、成功への最適なプロセスを共に作り上げます。当社の専門チームがパートナー企業のプロジェクトを成功まで導きます。


当社のAIを活用したサービスは、コンプライアンスを最優先しています。厳格な業界標準と規制を遵守し、より高度なセキュリティ対策を講じることで、パートナー企業の機密情報を常に保護いたします。